Edge strategy
Phases of edge deployment
We see the adoption of edge computing evolving in six phases:
- Business application migration
- Data democratization
- Edge ML inferencing
- Distributed query
- Federated machine learning
- Elastic edge
We will discuss each of these phases. Note that these phases do not need to follow sequentially.
Business application migration
The first phase of edge computing adoption is business application migration from the cloud back to on premise. Companies have updated their application architecture to be containerized. They need to have container orchestration on premise to run these applications, which means having a cluster of servers. Typically, the initial applications are not very large, so there is extra capacity in the edge servers. This situation will change quickly as companies add more and more applications to run on premise, especially machine learning applications.
Data democratization
The second phase of edge computing adoption is data democratization. Most companies have smart devices (IOT) that generate data in their locations, but no one is processing the data because there is no practical way to access it. With the previous phase, there is now a cluster on the factory floor, so there is now a means to deploy Apache Kafka. In this phase, companies can now connect the IOT data to Kafka and make the data accessible to data scientists.
Edge ML inferencing
Once the data is democratized at the edge, data scientists can start applying machine learning models to the data. Creating the machine learning models is called “training”, and today requires very large servers. Once the model is created, it does not require nearly as much compute power to run. Running the model is called “inferencing”. Inference is best done at the edge.
Distributed query
Currently companies copy all the data from their locations into a data lake to query, as shown in the figure below. Large data sets must be partitioned to enable parallel processing. Typically, the data is partitioned by the source location.
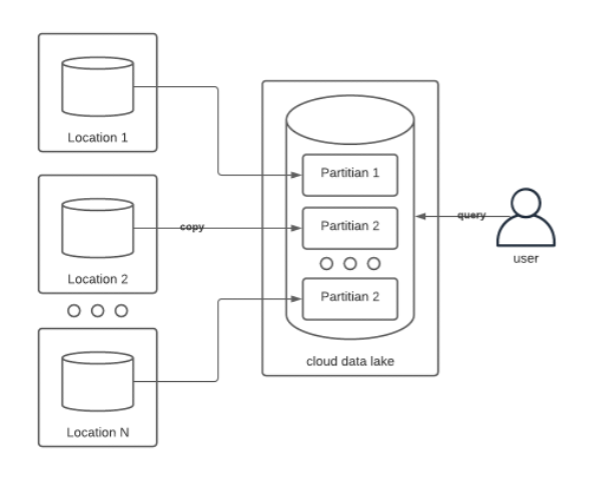

Once companies have deployed edge computing at scale, at hundreds or thousands of locations, a common epiphany occurs. Why move the data to the cloud to query? Why not query it at the edge instead?
There are startups already building this database technology. Once mature, companies will have an entirely new way of managing their data.
Federated machine learning
To create a machine learning model currently requires a very large server processing a very large data set. The price of the electricity to run these servers alone is $10,000 per month. They’re big. They’re expensive. And assembling the data set they crunch through is a large undertaking.

Federated learning changes all that, as in:
- A global model is deployed to many devices
- Each device iteratively optimizes the model on local data
- A server aggregates all the individual device optimizations to build a new global model
- The new model is sent to the devices and the process is repeated.
An example of federated learning is the auto complete suggestions that pop up on your phone while you are texting. There is a global model on your phone, but as you pick or don’t pick what is suggested, your phone is processing that. Your phone periodically sends the results of what it has seen of your behavior to the cloud. Your updates and those of millions of other users are aggregated and the new, smarter model is sent to your phone.
Federated learning and edge computing are going to be best friends. The implications are significant:
- Use the edge infrastructure to train models
- Models can continually train while deployed and working
- Save tons on moving data and expensive giant servers
- Models get continuously smarter
In particular, what federated learning enables data scientists to computing on data they do not own and cannot see.
- Remote execution of ML code
- Search and example data of remote data sets
- Differential privacy
- Secure multi-party computation
Elastic edge
The sixth phase of edge computing is elasticity. Elasticity is the ability to offer or use underutilized compute resources at the edge. During the few days around Black Friday, Amazon’s compute load doubles. That means for the other 350 days of the year, Amazon is not using half their servers. It is no coincidence that Amazon invented cloud computing. They found a way to offset the sunk cost of this over capacity by letting other companies rent their unused servers.
As edge computing grows, many companies will face similar underutilization. For example, a retail chain may only be open 12 hours a day. The other 12 hours, a large portion of their in-store servers will go unused. If the retail chain has thousands of locations, the cumulative unused compute power is significant. (See the discussion of edge scale earlier.) Such a company should be able to allow others to rent that compute power in those off hours.
Although many vendors, especially blockchain ones, anticipate this phase, no one has yet reached it. It requires that edge computing reach a much higher scale of deployment and technology maturity.
How to get started
Simple advice
My advice for getting started with edge computing can be summed up in three simple phrases:
- Start small
- Start now
- Scale quickly
Pick a single use case. Deploy it into a handful of locations. Demonstrate success quickly and then roll it out to all locations. Once the first use case is underway, pick your next use case and repeat the process.
Your team and your company will learn quickly. More importantly, they will learn the art of the possible. They will start thinking in terms of edge solutions and edge scale. None of us are clairvoyant enough to know all the amazing solutions that will arise with this new infrastructure.
Things to avoid
Here are some don’ts to keep in mind:
- Don’t lock your infrastructure into a single cloud provider. All the hyper scalers now provide edge as a service, but be aware. They are very large, very expensive and only work with their cloud.
- Don’t buy huge servers that you will eventually grow into. It will take too long to show a return on investment. Besides, technology changes so quickly that you may have to replace it before it pays off.
- Don’t assume that you must incur a capital expense just because you are deploying on premise. Edge as a service is a real and viable option.
- Don’t let your internal tech team build their own platform. We see this fail again and again. They have not considered all the challenges of scale. Besides, the worst possible vendor lock in is your own internal IT department.
- Don’t ignore scalability. High availability may not be a requirement when you first roll out, but it eventually will be. Your first edge use case will only be the beginning. More and more will follow.
- Don’t ignore your data infrastructure. So many solutions we see talk about deploying machine learning models, but ML models are useless unless they are consuming and producing data. You need to manage not only the applications but also the data they consume and produce.
Here to help
I hope that you have found this handbook helpful.
Hivecell is the best platform for edge computing available anywhere, period. We started five years ago with a clean sheet of paper and designed a complete solution to meet the unique needs of edge computing.
Just as import to you is not only the product but also the knowhow and experience that went into creating it. Hivecell and our partners are here to help you with your edge computing journey.
Call us, and let’s get started.